





引言
在Python编程中,文件读写是常见的操作。无论是处理日志数据、读取配置文件还是进行数据持久化,高效地读写文件都是提高程序性能的关键。本文将探讨几种在Python中实现高效文件读写的方法,帮助开发者提升文件操作的效率。
使用内置的文件操作方法
Python的内置文件操作方法提供了基础的读写功能,如`open()`, `read()`, `write()`, `close()`等。然而,这些方法在某些情况下可能不是最高效的。以下是一些提高文件读写效率的技巧:
使用缓冲
Python的文件对象默认是带缓冲的。这意味着它会在内部维护一个缓冲区,用于存储数据,从而减少磁盘I/O操作的次数。可以通过设置较大的缓冲区来提高读写效率。
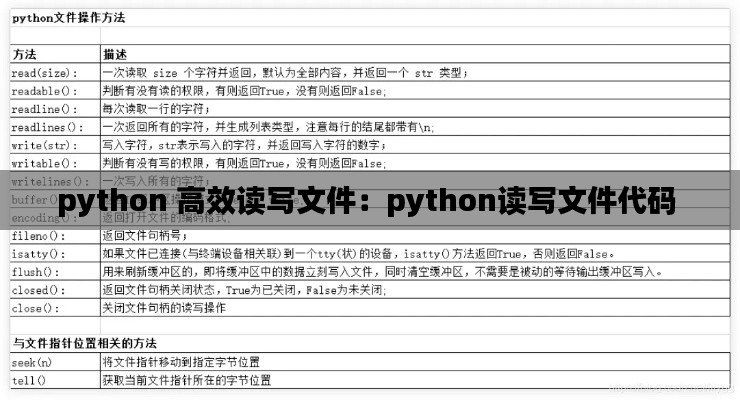
读取大文件时使用迭代器
当处理大文件时,一次性读取整个文件可能会消耗大量内存。使用迭代器可以逐行或逐块读取文件,这样可以有效管理内存使用。
使用`with`语句
`with`语句是Python中管理资源(如文件)的一种安全方式。它确保文件在使用后能够被正确关闭,从而避免资源泄漏。以下是一个使用`with`语句的例子:
with open('example.txt', 'r') as file:
for line in file:
print(line.strip())使用文件读写模式
Python提供了多种文件读写模式,如`'r'`(只读)、`'w'`(写入)、`'a'`(追加)等。正确选择文件模式可以避免不必要的错误和性能损耗。
使用`io`模块的`BufferedReader`和`BufferedWriter`
`io`模块提供了`BufferedReader`和`BufferedWriter`类,它们分别用于包装文件对象的读取和写入操作。这些类提供了缓冲机制,可以进一步提高性能。
import io
with io.BufferedReader(open('example.txt', 'r')) as reader:
while True:
line = reader.readline()
if not line:
break
print(line.strip())使用`pandas`和`numpy`进行高效数据处理
对于需要频繁读写大型数据集的情况,使用`pandas`和`numpy`等库可以显著提高效率。这些库提供了高效的DataFrame和NumPy数组数据结构,以及优化的数据读写功能。
使用`multiprocessing`进行并行读写
在某些情况下,可以将文件读写操作并行化以提高效率。Python的`multiprocessing`模块可以帮助实现这一点,通过将文件分割成多个部分,并使用多个进程同时读写。

结论
高效地读写文件是Python编程中的一项重要技能。通过使用内置方法、正确设置文件模式、利用缓冲机制、使用高效的库以及并行化操作,可以显著提高文件读写性能。掌握这些技巧将有助于开发者编写出更加高效和可靠的Python程序。
转载请注明来自上海贝贝鲜花礼品网,本文标题:《python 高效读写文件:python读写文件代码 》






 蜀ICP备2022005971号-1
蜀ICP备2022005971号-1
还没有评论,来说两句吧...